
Tuesday, October 21, 2014
Monday, October 20, 2014
Начини на кои може да се искористи овој избув на податоци Пост.02
Текстот е вториот дел од мојот семинарски труд за политиката академија "Friedrich Ebert"

Линк до првиот пост можете да најдете тука.
Следно прашање кое следствено доаѓа откако се воспостави фактот дека имаме проширување на изворот на податоци е како да го искористиме тоа? За да го одговориме ова прашање најдобро би било да се вратиме и да го резимираме процесот преку кој го добивме новиот систем. По истиот пат и самиот процес продолжува да еволуира. Делумно повторно причината е од бизнис карактер. Водени од мотивот за профит, партиципантите на овој пазар понудија нови услуги и отворија нови пазари. Истражувачкиот сектор исто така не заостана, тие веројатно водени од различен мотив, мотивот да се најдат нови методи за тестирање на хипотези, аналогно на новите услуги во бизнис секторот, ја проширија својата дејност цедејќи информации преку анализирање на однесувањето на луѓето во интернет сферата за академски цели. Сметам дека овој процес, каде пазарот се шири и евоулира, за тоа потоа да се пренесе во академскиот свет, каде процесот ќе достигне едно ново ниво кое пазарот го прифаќа, е еден процес кој често се случува во општеството и многу индустрии го искористиле неговиот бенефит иновирајќи нови производи и услуги. Нивото на сплотеност помеѓу академската сфера и пазарот е пожелно да биде што поблиску за бенефит на економијата. За жал кај нас спротивното е реалност. Меѓутоа, да се навратиме на првичното прашање, како да го искористиме овој нов извор на податоци? За да се одговори ова прашање најпрво ќе ги разгледаме изворите од кои се генерираат податоците и начините на кои може да се дојде до истите.
Извори кои генерираат податоци се нашите паметни уреди (во главном телефони и таблети), нашата активност на интернет, воглавном на социјалните мрежи (твитер, фејсбук, инстаграм…) како и сите останати уреди поврзани на интернет чии сигнали се зачувуваат за понатамошна обработка.
Користејќи ги апликациите на нашите телефони и таблети секојдневно генерираме голема количина на информации, како и им даваме пристап до нашите лични податоци на компаниите кои ги менаџираат овие апликации. Приватноста на податоците генерирани од нашите уреди моментално е “жешка” тема насекаде во светот. Во овој труд јас нема да навлегувам длабоко во темата, меѓутоа важно е да се разработи до некој степен за подобро разбирање на поширокиот контекст. Важно е да стане јасно дека на повеќето гиганти како Фејсбук или Гугл нашите лични податоци се клучни за успешноста на нивниот бизнис модел. Тие нудат платформа каде ние ги полниме нивните сајтови со содржина, а тие продаваат огласи на просторот на кој ние нудиме содржина. Проблемот со приватноста е во тоа што поради тоа што успехот на компаниите кои произведуваат апликации се наоѓа во тоа да соберат што подетални лични податоци кои ќе ги искористат за да понудат подобри услуги, или пак едноставно да ги продадат, ги наведува самите компании да ги заштитат самите податоци, за на крајот ние кои ги генерираме самите податоци немаме пристап до истите. Така популарно е прашањето кој е всушност правичниот сопственикот на паметните уреди (и на податоците)? Дали ние сме само корисници на уредите преку кои креираме бесплатна содржина и податоци за тие да се искористат во бизнисот на компаниите? Сметам дека најпрво треба да се повлече линија помеѓу оние податои кои се лични и сметаме дека не треба да ги споделиме со компаниите и оние податоци кои може да бидат јавни и да се искористат во истражувачкиот свет, како и за оптимизација при користење на техничките уреди. Моментално од нашите паметни уреди се добиваат информации за нашата мобилност, односно каде се движиме, како и целосен профил на нашите навики при користење на овие уреди. Од паметните уреди како таблетите и мобилните телефони се дознава повеќе отколку од компјутерите, поради облигацијата да се логираме со нашиот индентитет при користењето на мобилните апликации, додека компјутерите често се користени од повеќе лица. Прашањата во врска со приватноста се од несомено политички карактер и така треба да се пристапи кон нивно решавање. Меѓутоа ќе треба да се акумулира доволно воља и моќ за да се издејствува нивно решение кое ќе биде во полза на мнозинството.
Вториот извор на информации е од нашата активност на интернет, во главном од нашата активност на социјалните мрежи како што се Фејбук, Твитер, Инстаграм, Форсквер итн. Сите овие социјални мрежи се создадени со цел да вршат различни услуги, а со тоа и да соберат информации од различен карактер на социјалното живеење. Исто така сите овие соц. мрежи нудат пристап до дел од информациите кои може да ги искористиме за истражувања. Фејсбук содржи највеќе информации за тоа кого познаваме. Твитер содржи највеќе информации за нашето мислење на разни теми, како и локациони информации и информации во врска со нашите интереси. Инстаграм е социјална мрежа за споделување на слики и содржина во врска со нив, како и инфо за локацијата од каде е направена сликата. Форсквер е социјална мрежа за споделување на нашата локација со нашите контакти, профилирање и рејтинг на угостителските локали. По наведување на изворите на информации ќе наведам и како да ги искористиме овие извори.
Третиот извор на информации е интернетот на предмети. Овој извор на информации е сеуште во зачетна фаза. Меѓутоа се очекува во блиска иднина нашите уреди да бидат поврзани на интернет и да ‘знаат’ што треба да направат во дадени ситуации. Така, на пример нашите фрижидери ќе прават автоматски нарачки на намирници. Сите уреди како бравите, сијалиците итн. ќе бидат вмрежени преку безжична мрежа и ќе комуницираат со цел подобро да ни служат. Сите овие информации ќе се сочувуваат и ќе бидат субјект на бројни истражувања, дебати за приватност итн. Тоа се трите извори на дигитални информации, да видиме како може да ги добиеме и да ги искористиме.
Секоја од овие апликации нуди интерфејс или front end преку кој се логираме и ја користиме апликацијата. Исто така, секоја од овие апликации нуди и влез одзади или back end преку кој добиваме пристап до информации кои корисниците решиле да бидат јавни и компанијата решила да го дозволи пристапот до нив. Твитер е најотворен кога станува збор за искористување на информациите кои ги објавуваат корисниците на овие социјални мрежи. Преку задниот пристап може да добиеме пристап до текот на сите информации кои се објавуваат на твитер, додека се објавуваат. Твитер не нуди пристап до датабаза каде сите овие податоци се зачувани, за што би требало многу скапа инфраструктура поради тоа што зафаќаат премногу меморија. Твитер го нуди само пристапот до овие информации додека се објавуваат, во вистинско време (како прозор до текот на податоци), така што оние информации кои нас ни се потребни може да ги зачуваме во наша меморија и да ги искористиме. Твитер има и историска датабаза со твитови кои се предходно направени, меѓутоа ова е само 1% од сите твитови и до определено време во минатото, така што правење истражувања на база на историската меморија на твитер најверојатно нема да биде репрезентативно. Има компании кој ги сочувуваат сите твитови во датабази за понатамошно продавање на истите. За користењето на овој заден пристап до информациите ни е потребна авторизација, како и коринички профил на мрежата (ова станува збор и за влез во информациите на останатите социјални мрежи).
Задниот влез до податоците на Фејсбук функционира на сличен начин како и предходноспоменатион на Твитер. Повторни ни е потребно активен кориснички профил, информациите кои можеме да ги добиеме се јавните податоци, или податоците на нашите пријатели. Доколку сте и администратор на некоја Фејсбук страна, преку задниот влез можете да ги добиете сите податоци кои ви се достапни и кога ќе се логирате на Фејсбук. Податоците што се објавуваат од Фејсбук страните се јавни, меѓутоа има рестрикции доколку сакаме да го дознаеме идентитетот на лицата кои ги следат овие страни.
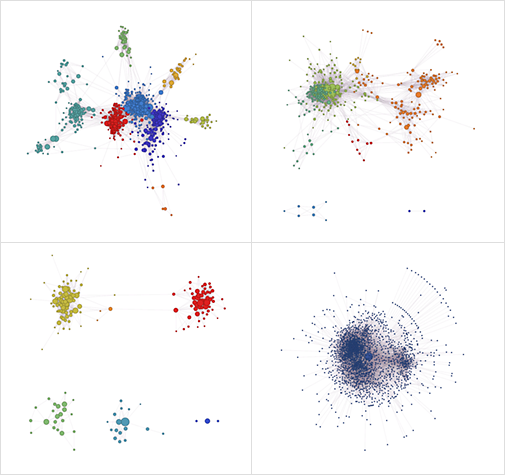
Одлична презентација за тоа какви информации може да извадиме од Фејсбук може да се најдат во извештајот на креаторот на софтверскиот пакет Mathematica и Wolfram/Wolfram Alpha, каде многу Фејсбук корисници ги донирале своите податоци за неговото истражување. Фејсбук генерира графи во кои може да видиме колку се поврзани нашите пријатели, поради тоа што може да видиме колку пријатели имаат нашите пријатели, како и кои од нив се пријатели еден со друг. Ова не се графици од оној тип на кој сме навикнати, туку под графа во овој случај се именува начинот на сочувување на податоци од страна на Фејсбук. Корисниците се меморираат како интерсекција на врски или node, додека врските помеѓу корисниците се нарекуваат edges. Ваквиот начин на зачувување на податоците ни овозможува детална визуализација од која може да извадиме многу заклучоци за социјалниот круг на корисникот чии податоци ги разгледуваме. На сликата подолу може да се видат графиците на 4 корисници со различен изглед.
Фугура.03 Извор: Wolfram Alpha Blog
Анализата која е направена ги дели групите на пријатели во кластери според сличност. Секој кластер е различно обоен. На сликата може да забележиме 4 различни типови на социјални мрежи. Во првата се забележуваат четири поголеми кластери со доста врски помеѓу различните кластери. Ова може да биде случај со човек кој на исто место растел и се образовал, така што иако запознал разни групи на луѓе во средна школа, факултет, маало, сепак и меѓу разните групи има конекции. Втората слика е слична на првата, со тоа што има два главни кластери кои се одделени, меѓутоа сепак има врски помеѓу. На третата слика гледаме четири кластери кои се изразито одделени, односно групите на пријатели не се познаваат едни со други. Четвртата слика гледаме еден доминирачки кластер, односно ова е тип на корисник чии пријатели се познаваат едни со други.
Инстаграм, социјалната мрежа за споделување на слики исто така нуди пристап до сите јавни податоци, освен демогравските, преку задниот влез. Принципот на кој функционира Инстаграм е таков што споделуваме слика, за која може да напишеме некаква порака и често во пораката се користи хаштаг за полесно пребарување. Исто така корисниците избираат дали ќе остават геолокација каде е направена сликата. Така користејќи го задниот влез на Инстаграм можеме да видиме во кој регион кои кампањи се најпопуларни, можеме да видиме какви слики се споделуваат во одреден регион, можеме да пребаруваме термини итн.
Последно, од Форсквер може да се добијат геолокациски информации. Форсквер не ни дава пристап до сите јавни податоци, туку ни дава пристап само до нашиот профил. Значи нема тек од информации кои може да го искористиме, меѓутоа може да избереме локација или пак локал и да добиеме 5 дестинации кои корисниците ги посетиле по посета на пребараната локација. Ова може да се направи за секоја следна локација, така што може да добиеме слика за тоа кои локали се посетувани од истите луѓе, а со тоа и да добиеме некоја шема за навиките на движење на различните групи на луѓе. Резултатите од ваквото пребарување на Форсквер може да се визуализираат во графа како онаа на Фејсбук.
Thursday, October 16, 2014
Што е тоа "Big Data"? Пост.01
Постот е прв дел од мојот семинарски труд за политичката академија "Friedrich Ebert": " Алтернативни Методи за Мерење на Јавното Мислење"
Терминот “Big Data” во последните неколку години го сретнуваме насекаде, меѓутоа неговото значење не е конкретно дефинирано, а со тоа и употребата на терминот често е арбитрарна. Користењето на терминот може да се поврза со два фундаментални концепти, едниот е во контекст на тоа дека обемот на податоците е преголем т.е. преголем за да биде обработен на еден компјутер, така што ‘big data’ се користи во контекст на тоа дека податоците кои се субјект на понатамошна обработка за да се добијат некакви резултати се преголеми во смисла на тоа колку меморија зафаќаат. Пример за ова е Гугл или Фејсбук кои чуваат детални податоци за стотици милиони нивни корисници. Инфраструктурата за зачувување на податоците и особено за нивно прикажување во краток временски интервал е многу комплексна, како и различна од она што се користело во минатото. Така, техничките инжињери создадоа нови методи за сочувување и прикажување на податоците соодветни со модерното време.
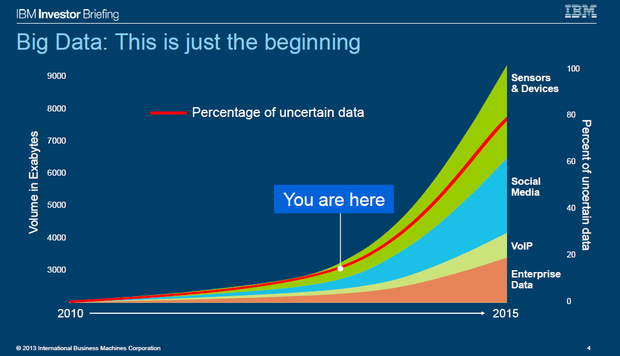
Вториот контекст во кој се користи изразот ‘big data’ е во смисла на обемот на податоци кои ги генерираат нашите хардверски и софтверски уреди. За разлика од контекстот на тоа дека податоците не ги собира во меморијата на еден компјутер, вториот контекст е во смисла на тоа дека едноставно луѓето генерираат многу повеќе податоци отколку во минатото. Доста познато истражување на гигантската компанија IBM доаѓа до наодот дека 90% од податоците генерирани во целата историја на чоештвото се генерирани во последниве 2 години. И растот на обемот на податоци кои чоештвото ги генерира не се успорува, туку напротив се повеќе расте (експоненцијално). Така, може да се каже дека терминот ‘big data’ се користи во два контексти, првиот за тежината на самите податоци и вториот за количината на податоци кои ги генерираат техничките уреди.

Фигура 01. Извор - Forbes.com
Фигура 02
По периодот на адаптација, во кој се промени системот за да се приспособи кон новите потреби, следуваше периодот на бројни дебати и истражувања околу тоа што се може да се направи со волку податоци. Најчесто мотивот за ваквите дебати е од профитабилен карактер, односно, компаниите водени од желба за профит ги истражуваат новите можности. Меѓутоа, како што подоцна ќе објаснам подетално, исто така и владите не заостанаа кога станува збор користење на овие податоци. Случајот со Американската агенција НСА (Национална Сигурносна Агенција) и Едвард Сноуден е повеќе од познат. По одвивањето на овие бројни адаптации, би рекол дека може да се каже дека влеговме во некоја трета фаза од процесот, каде новогенерираните податоци веќе се обработуваат и ова се случува насекаде: во бизнис сферите, во научните истражувања, мерење на јавното мислење, работата на владите итн. Во овој труд јас ќе се задржам на методите, кога станува збор за користењето на ‘big data’, за мерење на јавното мислење и за научни цели.
Терминот “Big Data” во последните неколку години го сретнуваме насекаде, меѓутоа неговото значење не е конкретно дефинирано, а со тоа и употребата на терминот често е арбитрарна. Користењето на терминот може да се поврза со два фундаментални концепти, едниот е во контекст на тоа дека обемот на податоците е преголем т.е. преголем за да биде обработен на еден компјутер, така што ‘big data’ се користи во контекст на тоа дека податоците кои се субјект на понатамошна обработка за да се добијат некакви резултати се преголеми во смисла на тоа колку меморија зафаќаат. Пример за ова е Гугл или Фејсбук кои чуваат детални податоци за стотици милиони нивни корисници. Инфраструктурата за зачувување на податоците и особено за нивно прикажување во краток временски интервал е многу комплексна, како и различна од она што се користело во минатото. Така, техничките инжињери создадоа нови методи за сочувување и прикажување на податоците соодветни со модерното време.
Вториот контекст во кој се користи изразот ‘big data’ е во смисла на обемот на податоци кои ги генерираат нашите хардверски и софтверски уреди. За разлика од контекстот на тоа дека податоците не ги собира во меморијата на еден компјутер, вториот контекст е во смисла на тоа дека едноставно луѓето генерираат многу повеќе податоци отколку во минатото. Доста познато истражување на гигантската компанија IBM доаѓа до наодот дека 90% од податоците генерирани во целата историја на чоештвото се генерирани во последниве 2 години. И растот на обемот на податоци кои чоештвото ги генерира не се успорува, туку напротив се повеќе расте (експоненцијално). Така, може да се каже дека терминот ‘big data’ се користи во два контексти, првиот за тежината на самите податоци и вториот за количината на податоци кои ги генерираат техничките уреди.
Фигура 01. Извор - Forbes.com
Фигура 02
По периодот на адаптација, во кој се промени системот за да се приспособи кон новите потреби, следуваше периодот на бројни дебати и истражувања околу тоа што се може да се направи со волку податоци. Најчесто мотивот за ваквите дебати е од профитабилен карактер, односно, компаниите водени од желба за профит ги истражуваат новите можности. Меѓутоа, како што подоцна ќе објаснам подетално, исто така и владите не заостанаа кога станува збор користење на овие податоци. Случајот со Американската агенција НСА (Национална Сигурносна Агенција) и Едвард Сноуден е повеќе од познат. По одвивањето на овие бројни адаптации, би рекол дека може да се каже дека влеговме во некоја трета фаза од процесот, каде новогенерираните податоци веќе се обработуваат и ова се случува насекаде: во бизнис сферите, во научните истражувања, мерење на јавното мислење, работата на владите итн. Во овој труд јас ќе се задржам на методите, кога станува збор за користењето на ‘big data’, за мерење на јавното мислење и за научни цели.
Subscribe to:
Posts (Atom)